|
Michelle Li I'm an incoming PhD student in computer science at UC Berkeley advised by Stuart Russell. My research is supported by the NSF GRFP. I obtained my BS in mathematics with computer science at MIT in 2022 where I conducted research in the Learning and Intelligent Systems lab. I then spent 2 exciting years at Waymo Research on the simulation team. I love music! Some of my favorite artists are: Radiohead, Animals as Leaders, HYUKOH, Tom Misch, Rina Sawayama, Sungazer, and Alfa Mist. I go to a lot of concerts 🤡. I'm always looking for new music so please send me your recs! Email / CV / Scholar / Twitter / Github / last.fm / Letterboxd |

|
ResearchI'm broadly interested in human-compatible AI and the role that tools from sequential decision-making might play in helping us get there. I'm currently thinking about assistance games, value alignment, model introspection, and how to get models to learn more like human students do. |
|
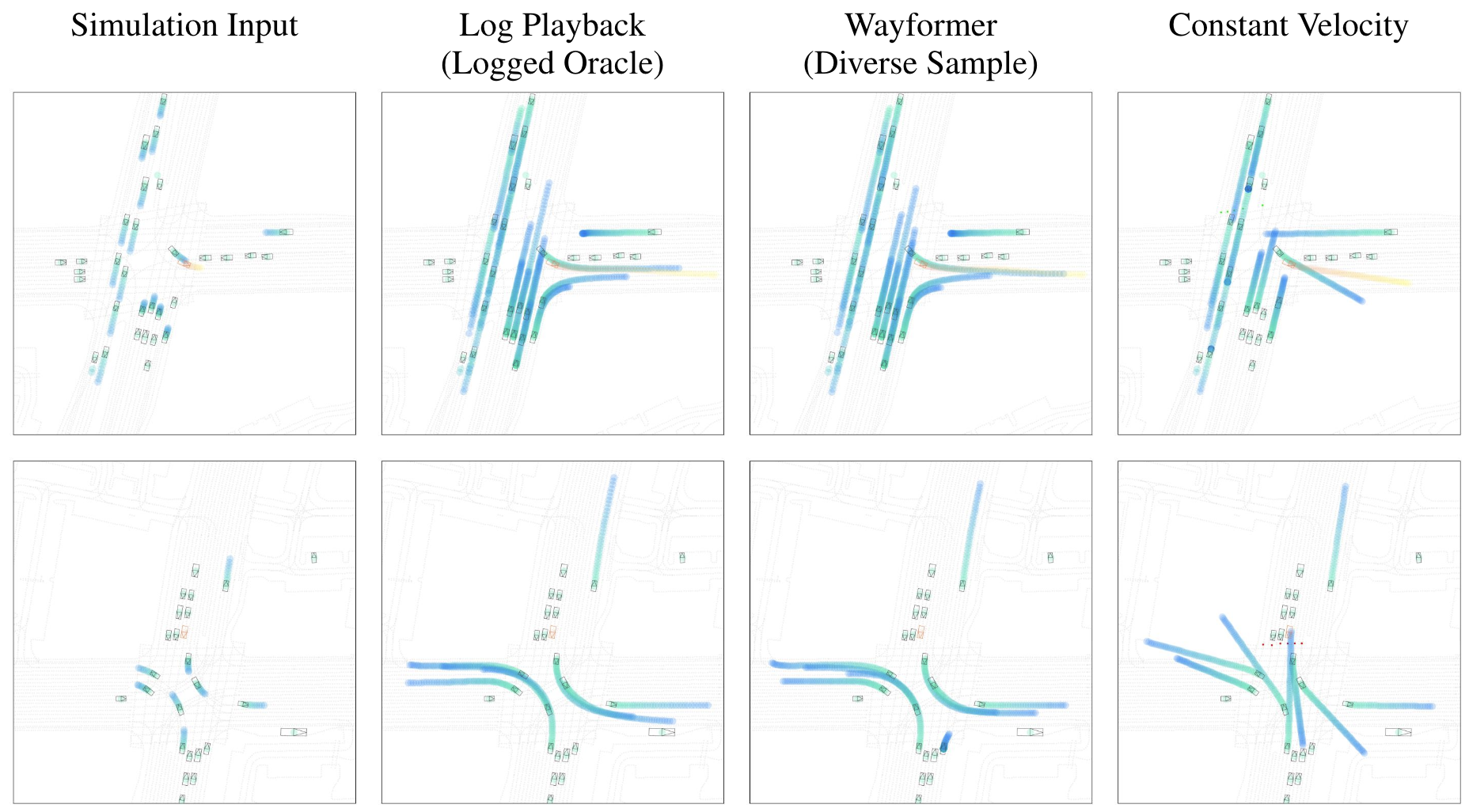
The Waymo Open Sim Agents Challenge
Nico Montali, ..., Michelle Li, ..., Shimon Whiteson, Brandyn White, Dragomir Anguelov NeurIPS 2023 Datasets and Benchmarks (Spotlight) Simulation with realistic, interactive agents represents a key task for autonomous vehicle software development. In this work, we introduce the Waymo Open Sim Agents Challenge (WOSAC). WOSAC is the first public challenge to tackle this task and propose corresponding metrics. The goal of the challenge is to stimulate the design of realistic simulators that can be used to evaluate and train a behavior model for autonomous driving. We outline our evaluation methodology, present results for a number of different baseline simulation agent methods, and analyze several submissions to the 2023 competition which ran from March 16, 2023 to May 23, 2023. The WOSAC evaluation server remains open for submissions and we discuss open problems for the task. |
|
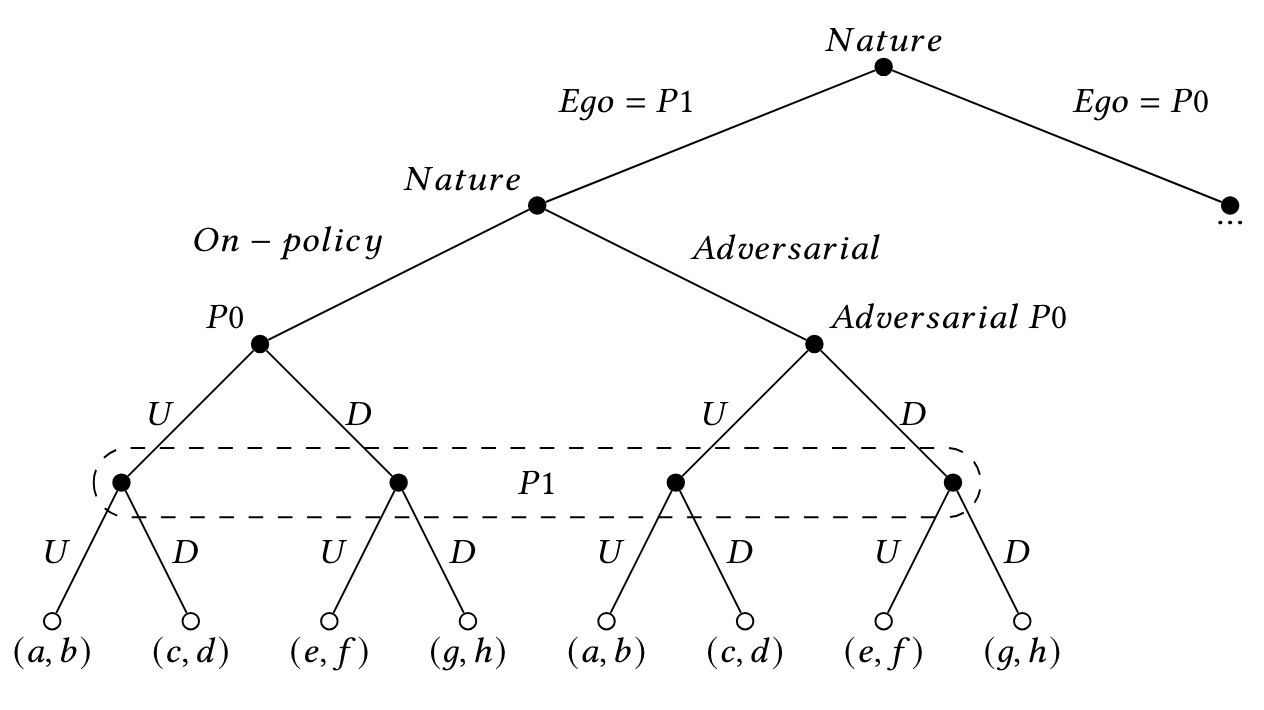
The Benefits of Power Regularization in Cooperative Reinforcement Learning
Michelle Li and Michael Dennis AAMAS 2023 (Finalist for Best Student Paper) Cooperative Multi-Agent Reinforcement Learning (MARL) algorithms, trained only to optimize task reward, can lead to a concentration of power where the failure or adversarial intent of a single agent could decimate the reward of every agent in the system. In the context of teams of people, it is often useful to explicitly consider how power is distributed to ensure no person becomes a single point of failure. Here, we argue that explicitly regularizing the concentration of power in cooperative RL systems can result in systems which are more robust to single agent failure, adversarial attacks, and incentive changes of co-players. To this end, we define a practical pairwise measure of power that captures the ability of any co-player to influence the ego agent's reward, and then propose a power-regularized objective which balances task reward and power concentration. Given this new objective, we show that there always exists an equilibrium where every agent is playing a power-regularized best-response balancing power and task reward. Moreover, we present two algorithms for training agents towards this power-regularized objective: Sample Based Power Regularization (SBPR), which injects adversarial data during training; and Power Regularization via Intrinsic Motivation (PRIM), which adds an intrinsic motivation to regulate power to the training objective. Our experiments demonstrate that both algorithms successfully balance task reward and power, leading to lower power behavior than the baseline of task-only reward and avoid catastrophic events in case an agent in the system goes off-policy. |

|
A Unifying Framework for Social Motivation in Human-Robot Interaction
Audrey Wang*, Rohan Chitnis*, Michelle Li*, Leslie Pack Kaelbling, Tomás Lozano-Pérez AAAI 2020 Plan, Activity, and Intent Recognition Workshop We develop a framework for social motivation in humanrobot interaction, where an autonomous agent is rewarded not only by its environment, but also based on the mental state of a human acting within this same environment. We concretize this idea by considering partially observed environments in which the agent’s reward function depends on the human’s belief. In order to effectively reason about what actions to take in such a setting, the agent must estimate both the environment state and the human’s belief. Although instantiations of this idea have been studied previously in various forms, we aim to unify them under a single framework. Our contributions are three-fold: 1) we provide a general POMDP framework for this problem setting and discuss approximations for tractability in practice; 2) we define several reward functions that depend on the human’s belief in different ways and situate them with respect to previous literature; and 3) we conduct qualitative and quantitative experiments in a simulated discrete robotic domain to investigate the emergent behavior of, and tradeoffs among, the proposed reward functions. |
|
Credits to Jon Barron's website template. |